darktaxa-project: interview David Young - Michael Reisch, 10-2019
David Young talking about his working-process, AI, little AI, GANs and flowers, in conversation with Michael Reisch, 10-2019

David Young: Learning Nature (b63d,2400,19,4,9,13,39,24), Inkjet-Print, 45x45cm, 2018
MR: David, you are a visual artist with a programming-background and you are currently working with AI and machine learning. For those who are not familiar with programming – like me for example – what is a „GAN“ and how does it work, and when was this technology developed?
DY: GANs, or Generative Adversarial Networks, were first developed in 2014. A GAN is made up of two parts, which have an “adversarial” relationship. The first part, the discriminator, is trained on a set of source images. Over time it develops an understanding of what those images represent. The second part of the GAN is the generator. It creates images from scratch and presents them to the discriminator, hoping that they will be mistaken as source images.
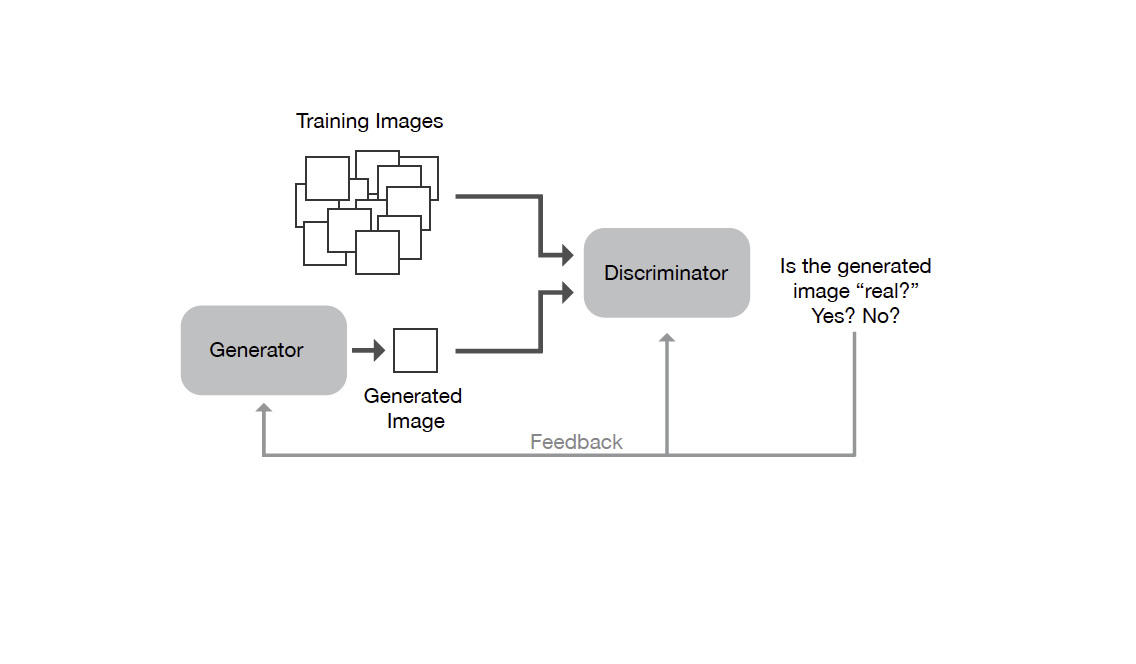
Diagram: David Young
MR: The “from scratch”-images, how does this work, how are they generated?
DY: At first the generator isn’t very good. It creates little more than static and the discriminator rejects the images. But, over time, it improves. Eventually it learns enough to trick the discriminator: it is able to generate images that are recognized being equivalent to, or as "real" as, the source images. At least to the degree that our discriminator understands them. What I find fascinating is the vast scale of the machine’s understanding. For at each stage of its training there exists an almost infinite number of possible images that it can generate. The challenge is finding the ones that are interesting.
MR: How can I imagine the “from-scratch-part”, the very beginning, is it like a rolling dice to find random coordinates for example?
DY: The dice metaphor is pretty accurate. The universe of possible images is unimaginably huge, In the work shown here, each image exists at a point in a 128 dimensional space. Technically this is referred to as the “latent space.” The number of unique images that the machine can create is the same as the number of points that are in this space, which is larger than the number of atoms in the universe. If you wanted to look at every single image, even at thousands per second, it would take longer than the age of the universe. And so navigating it is almost impossible. Instead what I do is pick a point at random and then explore the images that are "near" to it, looking for those that I find engaging. If I like what I’m finding, I’ll stop the training process. But if most of the images are poor, then I’ll keep training, hoping that the machine learns to make "better" images.
MR: This means, if I understand it right, first the “generator” learns to copy something, namely the source images? And then, as soon as the copies are good enough and accepted by the “discriminator”, the “generator” is able to create its own variations of the source images, within a certain range? I am interested in “copy” here also because the idea of copying, the “iconic” aspect, is basic to “photography”, or at least what we used to call “photography”.
DY: I don’t think that the idea of "copy" is correct. When it first starts, the machine doesn’t "know" anything, and so what it generates is static, nothing but random pixels. As it learns from the training images it begins to give shape to the static. In the beginning, because its knowledge is nascent (just starting) it makes only subtle changes to that static — we begin to see simple clustering and color groupings. It’s almost like how a baby sees the world, recognizes little but things with high contrast. As the machine learns, and as it knows more, it’s able to better "generate" and so the images get more recognizable.
MR: And in the end, after a successful training-process, what can it do, what is it normally used for?
DY: GANs are designed to be trained on huge quantities of images. Once trained they can generate new and unique images that are recognizable as “like” the training images. But GANs can also be used for things like “face aging,” creating text descriptions of the images, changing the styles of images, etc. I however am using very small data sets and so am limiting the machine’s ability to learn.
MR: This means the GANs you developed are reductions, they are scaled down, aren’t they? You call them “little AI” as far as I know, and I like this idea very much. I understand it as a sort of model, maybe also a comprehension-model for the “big AIs” used in “real” life, would you agree with this? When you scale the AI down to its basic functions, detached from the complex contexts it is usually part of, it gives some basic understanding of the AI-GAN-sphere, right?

David Young: Tabula Rasa, 18x30x3cm, Custom software (color, silent), LED screen, computer 2019
DY: Yes - absolutely. There is definitely a model that the machine has for what it was trained on. And that model is smaller than "big AI" both because the machine I use is smaller, and because I train it on much less data. The resulting model, the machine’s understanding of the world, is very limited and not entirely correct — it produces images that are "wrong." And I hope that in that "wrongness" we can begin to better understand the technology, as well as to create unique work.
MR: One more question, regarding the “discriminator’s” level of acceptance, how far is it possible to adjust it or program it? The relation between the programmer’s control and – maybe intentional – loss of control I find interesting here.
DY: I don’t want to dismiss your question… but I think that perhaps the idea of "programmer’s control" might be an outdated metaphor when talking about AI. For, unlike traditional programming, where the rules of the code are explicitly written out, AI is a bottom-up organic learning process.
MR: But you do “adjust” or influence the learning-process?
DY: Yes. There are several "hyperparameters" that can be adjusted to control how quickly the machine settles into its understanding of the subject. For example the machine can learn by experimenting with wildly different solutions and exploring them all, or it can accept its first solution and then spend its time refining it. Adjusting these parameters is surprisingly "dark art" and the numbers can vary wildly depending on the training material
MR: What about your own work, how do you handle this?
DY: Personally I’ve tried adjusting these values and it’s very hard to develop an intuition for what they actually do. In part this is because the training process is so slow (it can take days). But I think that because my training sets are so small, the adjustments I need to make are quite delicate. Instead I’ve been exploring how different types of source material impact the machine’s ability to learn. But I agree — this is a rich area for further exploration. If anything, the primary way that I influence the learning process is by curating what images I use to train the system.
MR: Do you see yourself more as a conceptual artist, or is what you call your “intuition” key to your working-process?
DY: I want to be clear that I am interested in the object, its appearance, and the aesthetic impact it has on the viewer. But I’m equally interested in using intermediaries and instructions as means to create. I think you could consider my practice a hybrid. But I do think that AI is a tool, like any other used by artists, just like a brush or a camera. And I am using that tool in my own particular way.
MR: Following this idea of AI as tool: before starting to work, do you actually already know more or less what you want, what the “AI-tool” should do? As output you want it to produce “flowers”, you already know that before starting, right? Or in other words, does the AI ever “invent something on its own”?

David Young: Tabula Rasa (b67m,1397,1), 45x45 cm, Inkjet-Print, 2019
David Young: Tabula Rasa (b67j,1357,1), 45x45 cm, Inkjet-Print, 2019
DY: As I work I start with an idea of what I want, and train the machine with material that I think will support that goal. The results can be unpredictable — sometimes strange, not always successful, but almost always interesting, and, on a good day, exciting. It’s hard to answer the question as to whether the machine ever comes up with something it’s never seen before because the results are always based on what it was trained on… it’s not going to invent a rose if it’s only seen lilies. But, in some of my work, training it on extremely small data sets, it has invented colors and shapes it never saw. So there is some sort of imagination happening in the machine that is different from how our minds work.
MR: I mean, in terms of inventing something, a random-generator would also do a very good job proposing colors, and give you even more choices at once, but this is something different, isn’t it? If I understand you right, the GAN can “understand” a certain pattern, and “invent” new forms or colors within this specific pattern, working with a mix of generative- and copy-processes? For example recently we all saw photorealistic pictures, showing faces of “new”, artificial persons, that were “invented” by GANs on the basis of thousands of photos of existing persons, within the “photorealistic-face pattern”.
DY: Exactly. A random-generator might create values (such as for colors), but little else. The GAN is much higher-level, working with the forms and patterns that make up an image.
MR: Can you also say something about your input-pictures? Where do they come from? For your “learning nature” series for instance, were you using found-footage, did you take photos yourself?
DY: I took the photos myself, of wild flowers gathered at my farm in upstate NY. I would estimate there were 100 or so that I used to train the machine.
MR: And how does your personal, your subjective selection-process work here? I mean, regarding the flowers that you collect and photograph? Is it random, do you follow aesthetic preferences? Like Colors for example? Or do you have a certain “objective” system, a concept?

David Young: Learning Nature, Inkjet-Prints, each 45x45cm, 2018
DY: For my flower images I tried several different ways of collecting and photographing the flowers. For example, if I took photos of the flowers in the wild, with other plants objects also in the frame, the results looked quite messy. But when I photographed them in my studio with a canvas backdrop, the results were much more pleasant. Again, not everything that the machine creates is successful, and so much of my task is that of a curator — choosing the images that I find beautiful. I was happy with these flowers for they reminded me of 17th century Dutch Master flower paintings — not aiming for accuracy, but with a sense of intense realism.
MR: Can you also say something about your abstract Tabula Rasa works? What does the GAN do here?
DY: The GAN is simply doing the same thing it does when looking at my flowers — trying to learn. But here, training it on as few as two solid colors, it’s incredibly constrained. What emerges are strange shapes, textures, and patterns — even sometimes new colors — that reveal the “materiality” of AI and GANs. I’m trying to understand and visualize the very basics of how this learning takes place. If anything, it reveals how radically different AI’s knowledge of its subject is from a humans.
MR: You also built a “little computer”, where one can see the “little AI” live at work?
DY: Yes - it’s in contrast or opposition to the huge companies working with AI. I want to see how little I could go, and if that might reveal a more intimate understanding of this vast technology. Here the little computer is pushed to its limits — it’s always on the verge of overheating, it’s extremely slow, and the display flickers. It’s a sculptural object that encapsulates all of what is being done with machine learning. It’s physical, self contained, it’s not in the cloud but right in front of your eyes, hanging on the wall!
MR: Talking about art: with the right hyperparameters as you say, the machine certainly is able to contribute “own“ forms, “own” colors, that we as humans wouldn’t easily come up with, right? On the other side we as humans decide, we curate the input and we do steer the output, as you also say, and we do this by using our subjective, human parameters, our cultural conditioning. Then who is the artist? You? The AI? Both?
DY: I have no hesitation to say that I am the artist, and that the GAN is the tool. The machine is comparable to a camera used by the photographer, or a brush used by the painter. Or a computer used by a generative artist. It may seem to be intelligent, because the technology is so foreign and difficult to understand, but it’s just code, doing mathematical operations. If anything the label “artificial intelligence” is a distraction from a new category of technology that’s on the verge of transforming society.
MR: If you are the artist – and I think there is no doubt about this – do we encounter something like a “machinic other” in your pictures? Is there anything like this at all? Or do we always encounter our own aesthetic decisions and opinions, based on our cultural heritage, upbringing, do we always only encounter ourselves in the mirror of technology we invent, produce? In a text of yours you were talking about “input-bias” in this regard, emphasizing the dependence of output on the necessarily subjective choice of input, is this also something to mention here?
DY: Yes - I do believe that there is some sort of “machinic other.” This exists because the machine’s understanding of the material, via its neural network, is so different from our own. As a result the work exhibits a materiality which is unique to AI, machine learning, and GANs. But it doesn’t exist in isolation. The machine’s knowledge is the product of us — to your point, yes, embedding all of our cultural history. The machine is only as smart as what it is trained on. But we need to acknowledge that almost all training material contains bias. The concern in large systems is that the bias can embed and reinforce existing negative racial or social patterns. In my work I acknowledge the bias comes from my personal aesthetics and try to work with it.
MR: As a resume, I don’t know if you agree with me here: the system is not working without us, as humans, at least at this point, and the ability to create art still distinguishes us from the machine, which I find somehow comforting.
David Young, Michael Reisch, 10-2019